 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust in Vision-Language Models: Insights from a Participatory User Workshop
Nov 17, 2025With the growing deployment of Vision-Language Models (VLMs), pre-trained on large image-text and video-text datasets, it is critical to equip users with the tools to discern when to trust these systems. However, examining how user trust in VLMs builds and evolves remains an open problem. This problem is exacerbated by the increasing reliance on AI models as judges for experimental validation, to bypass the cost and implications of running participatory design studies directly with users. Following a user-centred approach, this paper presents preliminary results from a workshop with prospective VLM users. Insights from this pilot workshop inform future studies aimed at contextualising trust metrics and strategies for participants' engagement to fit the case of user-VLM interaction.
Mapping User Trust in Vision Language Models: Research Landscape, Challenges, and Prospects
May 08, 2025The rapid adoption of Vision Language Models (VLMs), pre-trained on large image-text and video-text datasets, calls for protecting and informing users about when to trust these systems. This survey reviews studies on trust dynamics in user-VLM interactions, through a multi-disciplinary taxonomy encompassing different cognitive science capabilities, collaboration modes, and agent behaviours. Literature insights and findings from a workshop with prospective VLM users inform preliminary requirements for future VLM trust studies.
Mutual Understanding between People and Systems via Neurosymbolic AI and Knowledge Graphs
Apr 15, 2025This chapter investigates the concept of mutual understanding between humans and systems, positing that Neuro-symbolic Artificial Intelligence (NeSy AI) methods can significantly enhance this mutual understanding by leveraging explicit symbolic knowledge representations with data-driven learning models. We start by introducing three critical dimensions to characterize mutual understanding: sharing knowledge, exchanging knowledge, and governing knowledge. Sharing knowledge involves aligning the conceptual models of different agents to enable a shared understanding of the domain of interest. Exchanging knowledge relates to ensuring the effective and accurate communication between agents. Governing knowledge concerns establishing rules and processes to regulate the interaction between agents. Then, we present several different use case scenarios that demonstrate the application of NeSy AI and Knowledge Graphs to aid meaningful exchanges between human, artificial, and robotic agents. These scenarios highlight both the potential and the challenges of combining top-down symbolic reasoning with bottom-up neural learning, guiding the discussion of the coverage provided by current solutions along the dimensions of sharing, exchanging, and governing knowledge. Concurrently, this analysis facilitates the identification of gaps and less developed aspects in mutual understanding to address in future research.
Neuro-Symbolic Scene Graph Conditioning for Synthetic Image Dataset Generation
Mar 21, 2025



As machine learning models increase in scale and complexity, obtaining sufficient training data has become a critical bottleneck due to acquisition costs, privacy constraints, and data scarcity in specialised domains. While synthetic data generation has emerged as a promising alternative, a notable performance gap remains compared to models trained on real data, particularly as task complexity grows. Concurrently, Neuro-Symbolic methods, which combine neural networks' learning strengths with symbolic reasoning's structured representations, have demonstrated significant potential across various cognitive tasks. This paper explores the utility of Neuro-Symbolic conditioning for synthetic image dataset generation, focusing specifically on improving the performance of Scene Graph Generation models. The research investigates whether structured symbolic representations in the form of scene graphs can enhance synthetic data quality through explicit encoding of relational constraints. The results demonstrate that Neuro-Symbolic conditioning yields significant improvements of up to +2.59% in standard Recall metrics and +2.83% in No Graph Constraint Recall metrics when used for dataset augmentation. These findings establish that merging Neuro-Symbolic and generative approaches produces synthetic data with complementary structural information that enhances model performance when combined with real data, providing a novel approach to overcome data scarcity limitations even for complex visual reasoning tasks.
More than the Sum of Its Parts: Ensembling Backbone Networks for Few-Shot Segmentation
Feb 09, 2024



Semantic segmentation is a key prerequisite to robust image understanding for applications in \acrlong{ai} and Robotics. \acrlong{fss}, in particular, concerns the extension and optimization of traditional segmentation methods in challenging conditions where limited training examples are available. A predominant approach in \acrlong{fss} is to rely on a single backbone for visual feature extraction. Choosing which backbone to leverage is a deciding factor contributing to the overall performance. In this work, we interrogate on whether fusing features from different backbones can improve the ability of \acrlong{fss} models to capture richer visual features. To tackle this question, we propose and compare two ensembling techniques-Independent Voting and Feature Fusion. Among the available \acrlong{fss} methods, we implement the proposed ensembling techniques on PANet. The module dedicated to predicting segmentation masks from the backbone embeddings in PANet avoids trainable parameters, creating a controlled `in vitro' setting for isolating the impact of different ensembling strategies. Leveraging the complementary strengths of different backbones, our approach outperforms the original single-backbone PANet across standard benchmarks even in challenging one-shot learning scenarios. Specifically, it achieved a performance improvement of +7.37\% on PASCAL-5\textsuperscript{i} and of +10.68\% on COCO-20\textsuperscript{i} in the top-performing scenario where three backbones are combined. These results, together with the qualitative inspection of the predicted subject masks, suggest that relying on multiple backbones in PANet leads to a more comprehensive feature representation, thus expediting the successful application of \acrlong{fss} methods in challenging, data-scarce environments.
Surgical fine-tuning for Grape Bunch Segmentation under Visual Domain Shifts
Jul 03, 2023



Mobile robots will play a crucial role in the transition towards sustainable agriculture. To autonomously and effectively monitor the state of plants, robots ought to be equipped with visual perception capabilities that are robust to the rapid changes that characterise agricultural settings. In this paper, we focus on the challenging task of segmenting grape bunches from images collected by mobile robots in vineyards. In this context, we present the first study that applies surgical fine-tuning to instance segmentation tasks. We show how selectively tuning only specific model layers can support the adaptation of pre-trained Deep Learning models to newly-collected grape images that introduce visual domain shifts, while also substantially reducing the number of tuned parameters.
Commonsense Spatial Reasoning for Visually Intelligent Agents
Apr 01, 2021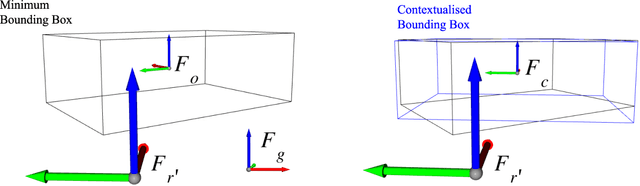
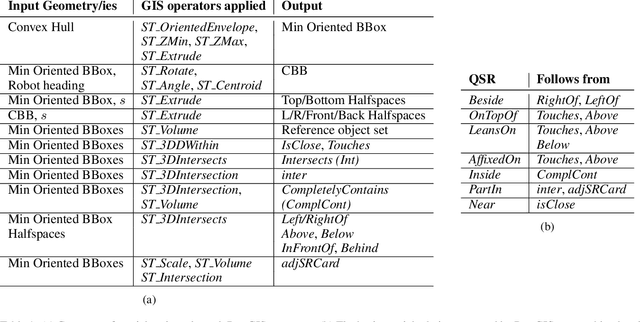
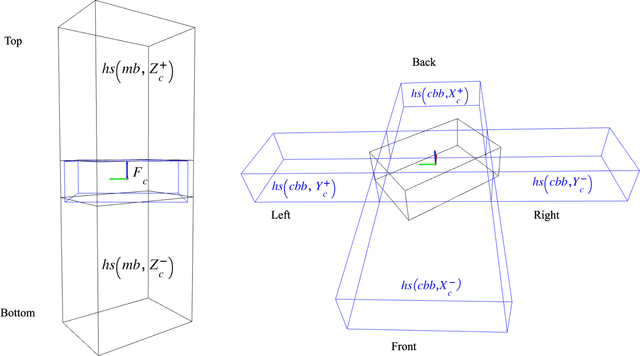
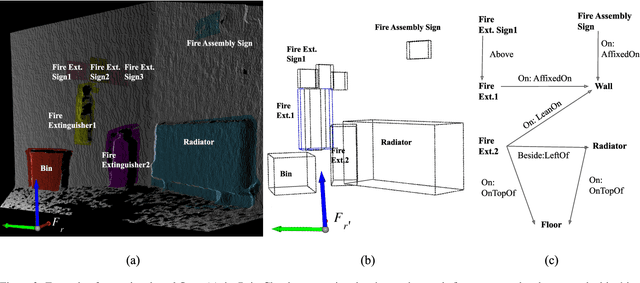
Service robots are expected to reliably make sense of complex, fast-changing environments. From a cognitive standpoint, they need the appropriate reasoning capabilities and background knowledge required to exhibit human-like Visual Intelligence. In particular, our prior work has shown that the ability to reason about spatial relations between objects in the world is a key requirement for the development of Visually Intelligent Agents. In this paper, we present a framework for commonsense spatial reasoning which is tailored to real-world robotic applications. Differently from prior approaches to qualitative spatial reasoning, the proposed framework is robust to variations in the robot's viewpoint and object orientation. The spatial relations in the proposed framework are also mapped to the types of commonsense predicates used to describe typical object configurations in English. In addition, we also show how this formally-defined framework can be implemented in a concrete spatial database.
Fit to Measure: Reasoning about Sizes for Robust Object Recognition
Oct 27, 2020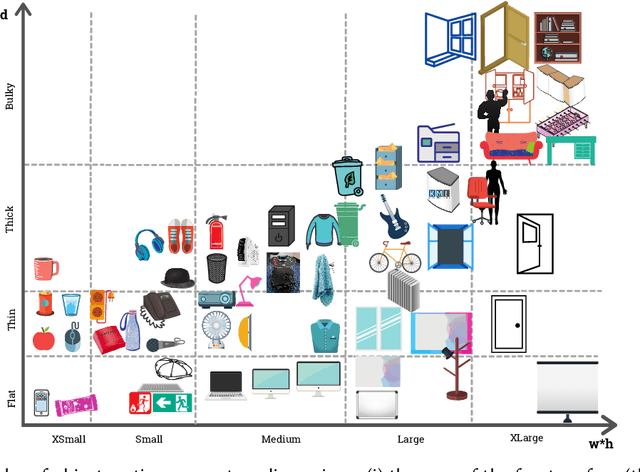

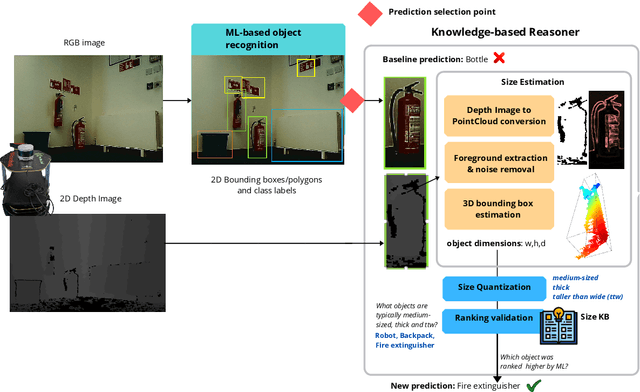
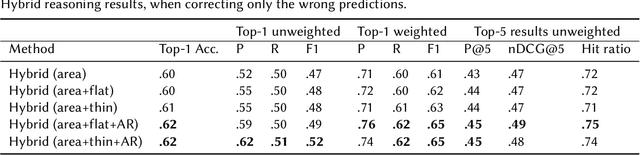
Service robots can help with many of our daily tasks, especially in those cases where it is inconvenient or unsafe for us to intervene: e.g., under extreme weather conditions or when social distance needs to be maintained. However, before we can successfully delegate complex tasks to robots, we need to enhance their ability to make sense of dynamic, real world environments. In this context, the first prerequisite to improving the Visual Intelligence of a robot is building robust and reliable object recognition systems. While object recognition solutions are traditionally based on Machine Learning methods, augmenting them with knowledge based reasoners has been shown to improve their performance. In particular, based on our prior work on identifying the epistemic requirements of Visual Intelligence, we hypothesise that knowledge of the typical size of objects could significantly improve the accuracy of an object recognition system. To verify this hypothesis, in this paper we present an approach to integrating knowledge about object sizes in a ML based architecture. Our experiments in a real world robotic scenario show that this combined approach ensures a significant performance increase over state of the art Machine Learning methods.
Towards a Framework for Visual Intelligence in Service Robotics: Epistemic Requirements and Gap Analysis
Mar 13, 2020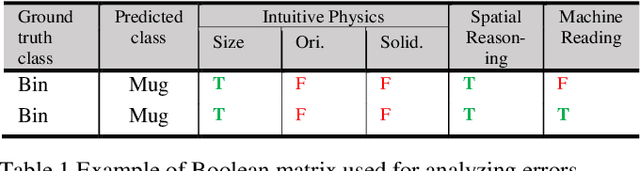
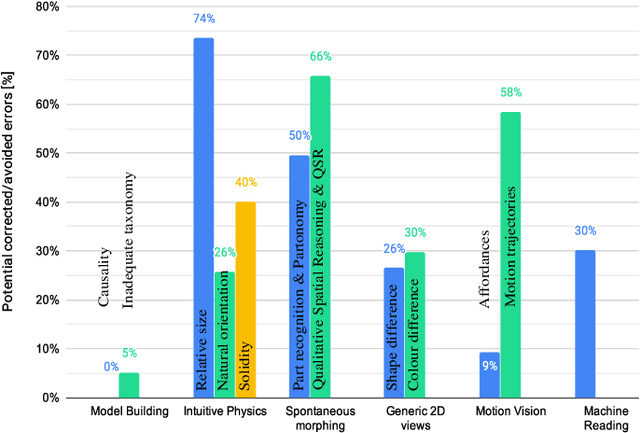
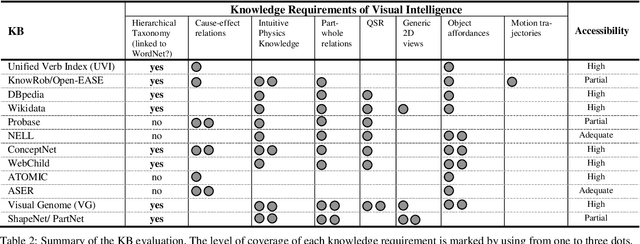
A key capability required by service robots operating in real-world, dynamic environments is that of Visual Intelligence, i.e., the ability to use their vision system, reasoning components and background knowledge to make sense of their environment. In this paper, we analyze the epistemic requirements for Visual Intelligence, both in a top-down fashion, using existing frameworks for human-like Visual Intelligence in the literature, and from the bottom up, based on the errors emerging from object recognition trials in a real-world robotic scenario. Finally, we use these requirements to evaluate current knowledge bases for Service Robotics and to identify gaps in the support they provide for Visual Intelligence. These gaps provide the basis of a research agenda for developing more effective knowledge representations for Visual Intelligence.
Guess What's on my Screen? Clustering Smartphone Screenshots with Active Learning
Jan 10, 2019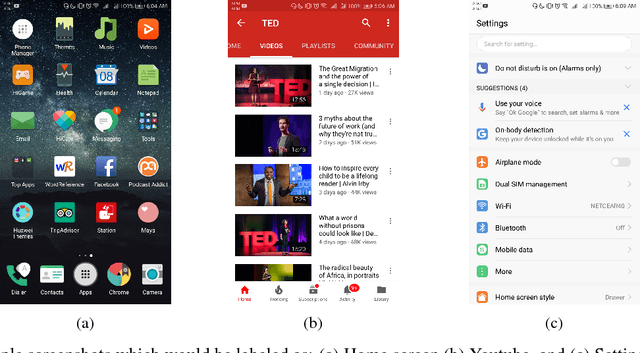
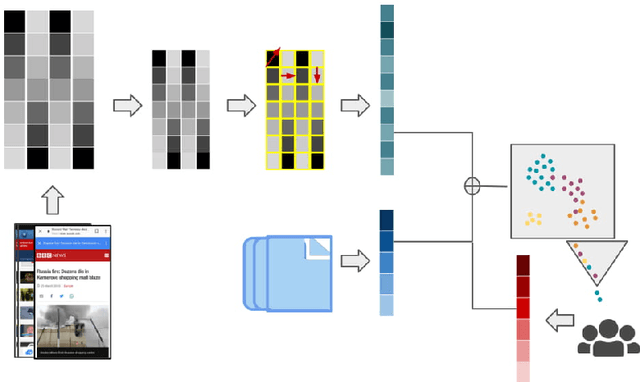
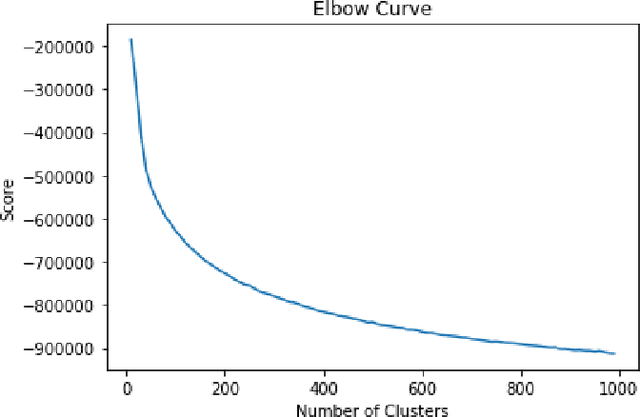
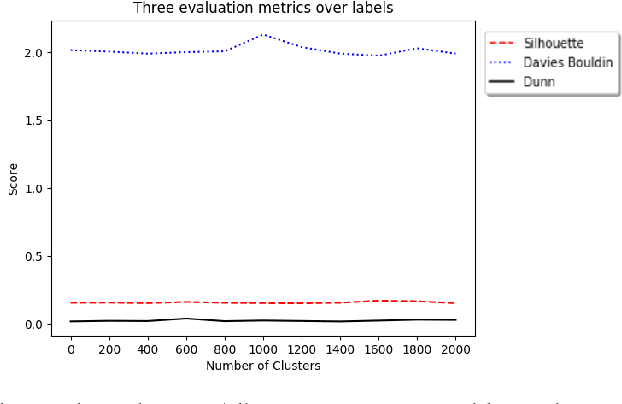
A significant proportion of individuals' daily activities is experienced through digital devices. Smartphones in particular have become one of the preferred interfaces for content consumption and social interaction. Identifying the content embedded in frequently-captured smartphone screenshots is thus a crucial prerequisite to studies of media behavior and health intervention planning that analyze activity interplay and content switching over time. Screenshot images can depict heterogeneous contents and applications, making the a priori definition of adequate taxonomies a cumbersome task, even for humans. Privacy protection of the sensitive data captured on screens means the costs associated with manual annotation are large, as the effort cannot be crowd-sourced. Thus, there is need to examine utility of unsupervised and semi-supervised methods for digital screenshot classification. This work introduces the implications of applying clustering on large screenshot sets when only a limited amount of labels is available. In this paper we develop a framework for combining K-Means clustering with Active Learning for efficient leveraging of labeled and unlabeled samples, with the goal of discovering latent classes and describing a large collection of screenshot data. We tested whether SVM-embedded or XGBoost-embedded solutions for class probability propagation provide for more well-formed cluster configurations. Visual and textual vector representations of the screenshot images are derived and combined to assess the relative contribution of multi-modal features to the overall performance.